Wist: Immersive Memories
Spatial capture, processing, & playback on iOS, Quest, Vision Pro
Role
Founder, CEO (Design, Eng, Product, R&D)
Date
May 2021 - February 2026
Founded a spatial computing company that turned video into immersive, replayable memories across iOS, Quest, and Vision Pro. Raised ~1M. Built the team. Designed and developed the volumetric capture, processing, and playback stack that processed over 8,800 memories and 18,600+ waitlist sign ups.
Capture & relive memories spatially
just by taking a video
Capture
Take a video in Wist, or import from camera roll.

Process
On device for an initial version. Higher quality processes on the cloud.
Step inside
Relive memories on iOS, Quest, or Vision Pro.
Press play
Why immersive memories?
Product thesisTake a video. Step inside. Enhance forever.
Immersive media is incredibly compelling, even more when it is your own memories. I saw where the tech was going, in part from my time at Samsung, but no one was tacking the hard problem. Companies were going after high-end multi-camera rigs, or static photogrammetry, or wholly generated 2D video.
Wist’s unique perspective and challenges were
- Dynamic, living memories. A memory must be as alive as the original moment. Not static photogrammetry scans or flat media.
- As easy as taking a video. Just capture or import. We must match what people already do. The tech does the hard part.
- Continuous improvement. Every capture must be able to be reprocessed with our latest version to enhance the reconstruction.
And, it was personal: I was about to have my first kid.
What I built & led
Forest & the treesI led the company from research prototypes through product development, fundraising, and ultimately through shutdown.
We grew to four at our height, a cross-functional team. I operated across design, engineering, product, and R&D, building the core tech while defining product direction.
I wore many hats and used all the tools in my toolbox.
Founder+CEO 🙋🏻♂️
- Defined product vision, roadmap
- Raised ~$1M from VCs and angels (lead: Long Journey Ventures)
- Hired and led a small, highly technical team
- User research and metrics
Designer 👨🏻🎨
- Crafted new paradigms for interacting with spatial media in headsets and on mobile
- Created beautiful experiences, focused on what matters
Engineer 👨🏻💻
- Led ML model and rectification methods implementation and orchestration
- Crafted new paradigms for interacting with spatial media in headsets and on mobile
- Led and built depth video sequence optimization, video encoding, shader development, user data backend, performance optimization, and interaction systems - across mobile, headsets, and multiple backends
-
- Swift
- Python
- JavaScript/TypeScript
- C#
- HLSL
- Metal Shading Language
- HTML/CSS
-
- SwiftUI
- AVFoundation
- Metal
- ARKit
- RealityKit
- OpenCV
- Open3D
- PyTorch
- Streamlit
- Scikit Image
- Rerun
- Anaconda
- Git
- Mixpanel
- Firebase (Firestore, Storage, Auth, Cloud Functions, +)
- FFMPEG
- Loops
- Jekyll
- Node
- Mocha
- Arduino
- LLM/AI Assisted Workflows
-
- Unity
- Blender
- Figma
- Sketch
- Premiere Pro
- DaVinci Resolve
- Rive
- Qualitative & Quantitative User Research
- Procreate
- Keynote
- Reality Scan / Reality Capture

Every moment is special, from first heartbeats to first breaths to first laughs to first steps.
Accolades & praise
User feedback
“It’s much more immersive than watching the apple spatial videos.”
“Even though it was something I had recorded only minutes ago, it nearly brought tears to my eyes.”
Traction
- 18,600+ waitlist sign ups
- 1,700+ users
- 8,800+ memories captured
Covered in media
Interviews in Vice/Motherboard, This Week in Startups, The Pitch, Freethink, Upload VR, and XR AI Spotlight.

Wist used in the production of “First Sight”.
Used in short film
Worked with Andrew McGee (director) to create a version of Wist that could be used on set to replace some VFX work. See the film.
Product
It has to be easy and just workWist was an end-to-end spatial media platform for parents with young kids.
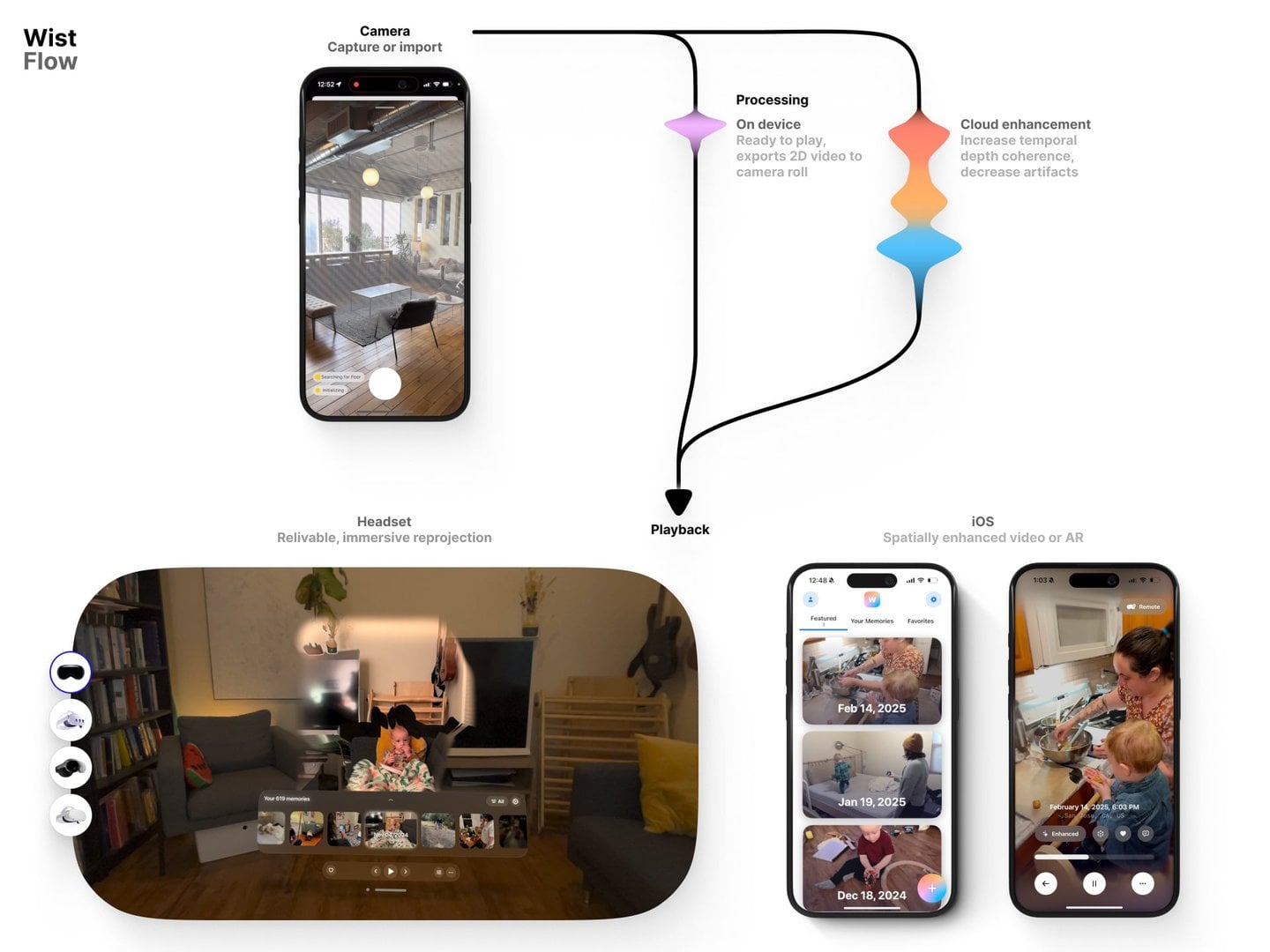
Wist flow. Capture or import. Process on device and enhance in the cloud. Relive in headset or on mobile.
The entire product experience balanced two things:
- familiarity with existing patterns and
- novel, spatial extensions into new experiences
iOS capture, browsing, & playback
Spatial capture that feels like video
Each capture records video + depth + camera pose + intrinsics, all at 30-60fps. We directly encoded into an internal format that preserves a higher depth range and helps playback.
Users could also import 2D video for a “spatial upconversion”.
Capturing feels like video. We use a depth effect at camera init to hint at the difference between Wist and other camera apps. Dismissable. Hints at depth capture. Surfaces most important camera performance notices (e.g. phone is hot).
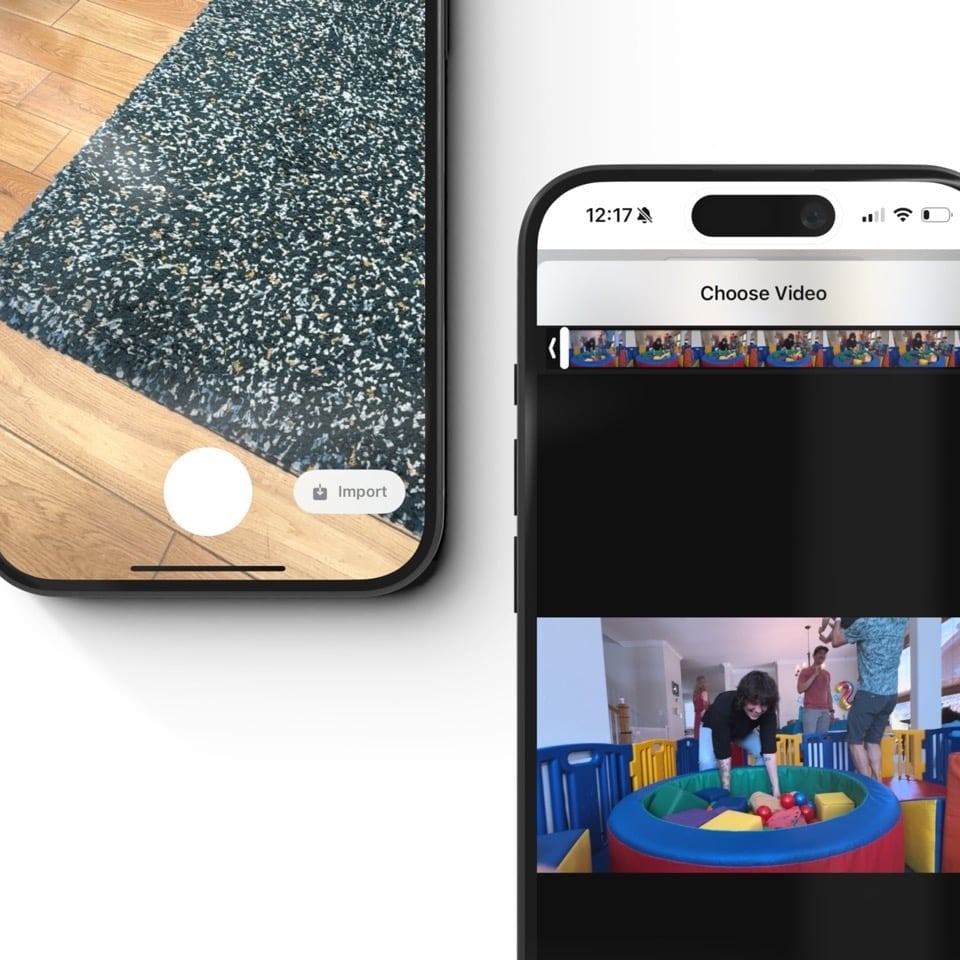
Importing is delightfully unremarkable. The output is what is special.
Beyond 2D playback, even on flat screens
It was tricky to balance “this is familiar” and “this is giving me way more”. My design principle was that any effects, including depth, must be additive.
Spatial scrubbing: scrubbing the playback position changes how the scene camera follows the original camera position, helping the user understand the depth of the scene. Smoothness comes from our work on smoothing our 3D camera positioning math.
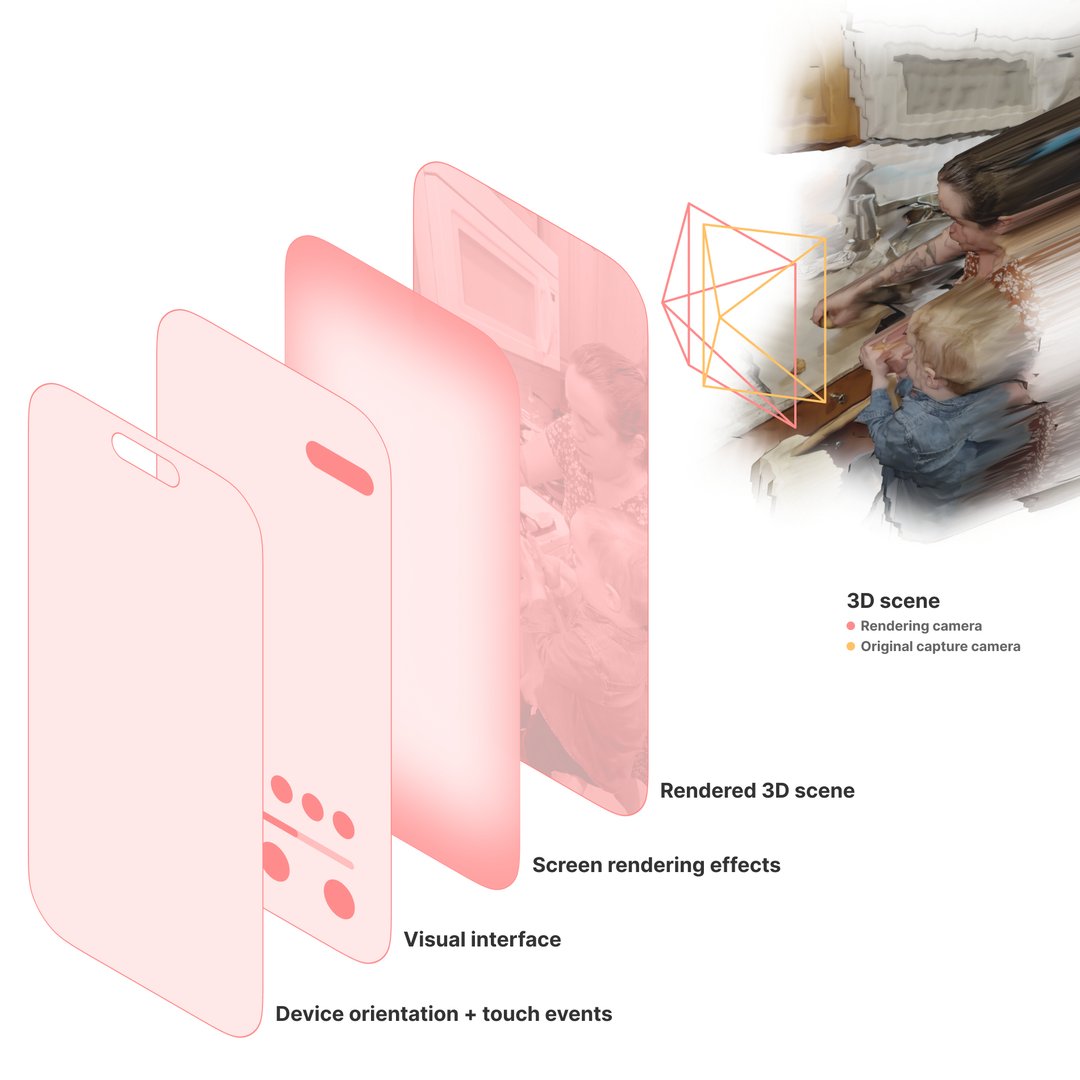
Re-rendering the 3D scene. By rendering from a new camera position, smartly coupled to the capture position, I was able to create smoother playback; enhance parallax perception; and blend inputs from device orientation, touch events, and the original camera poses.
Always up: with a known world orientation frame, a shaky camera gets correctly oriented each frame.
Smoothing details: lots of tuning went into how the elements of the scene hierarchy follow each other smoothly, and how those intersect continuously with the user's actions.
Modeless interaction: users can drag-to-orbit or tilt their phone to see around a scene. Our camera system allows for continuous and softly constrained influence from various sources without locking the user into a mode.
Remote play: to help folks sharing their content in the same space. One user can trigger a memory from their phone while a second user is in the headset.
Other iOS details
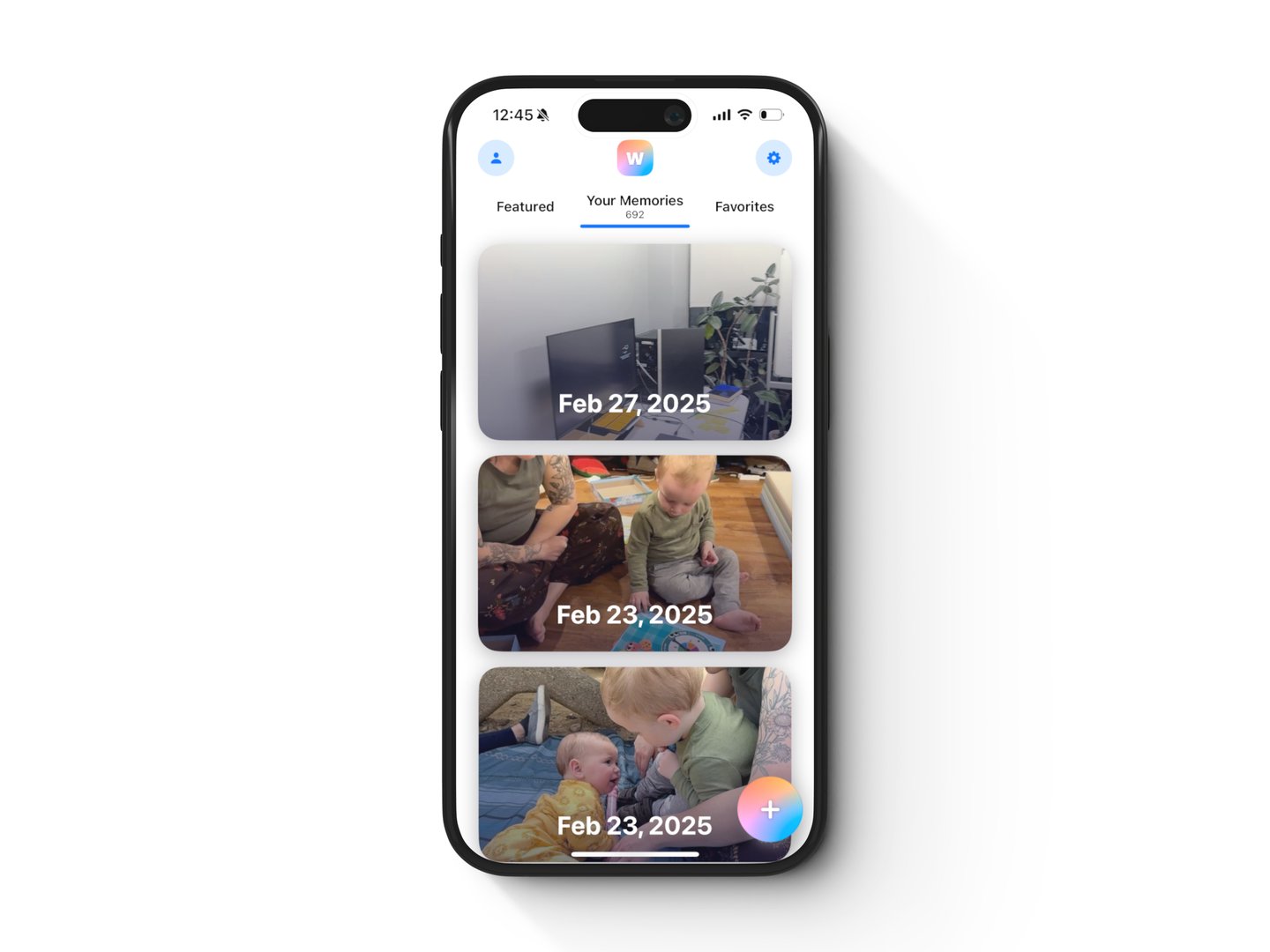
Feed. Elevation is used to give prominence to memories and capture button, communicated via soft shadow layers. Swipe to featured or favorites.
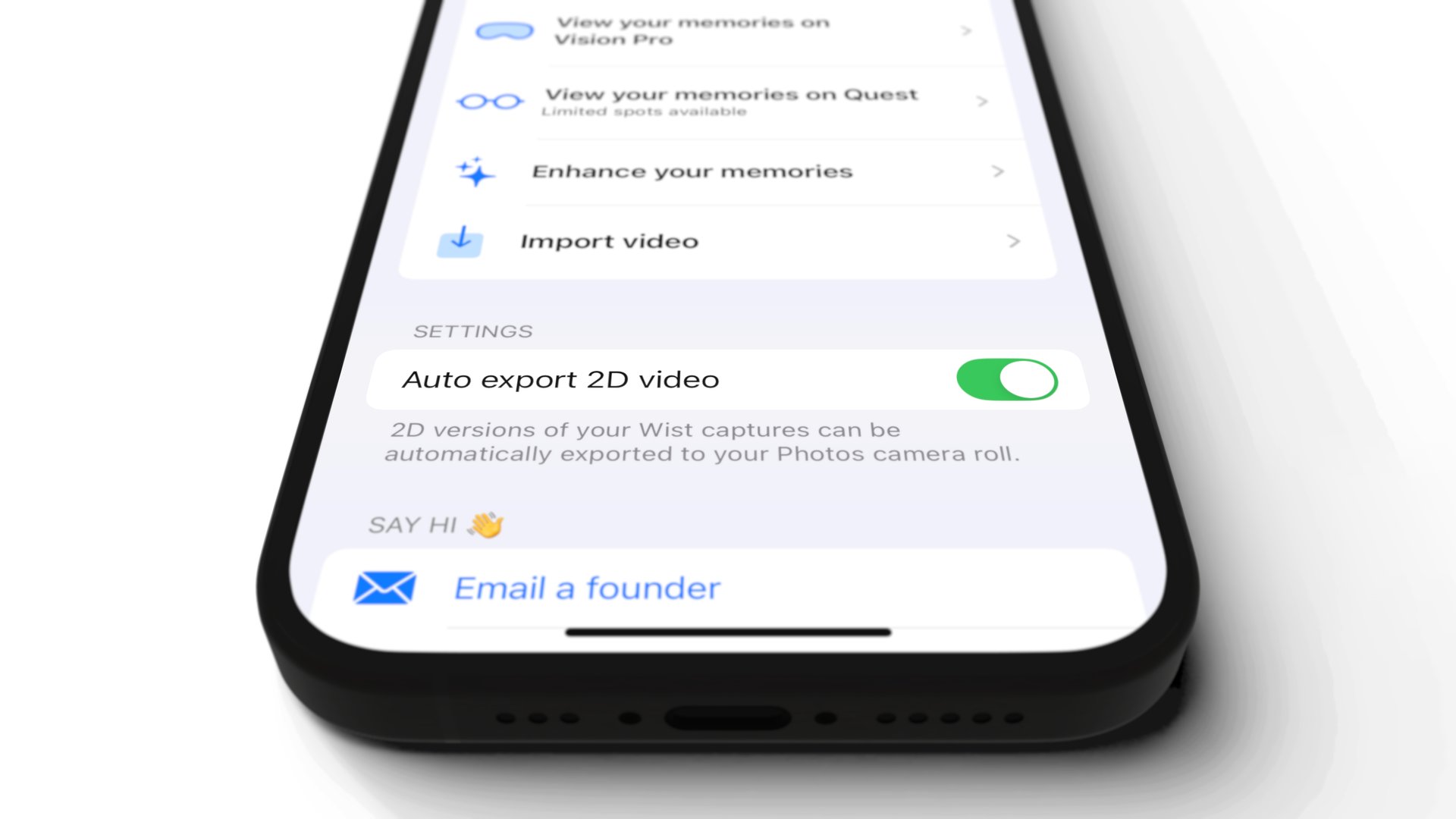
Auto export. To decrease switching costs, Wist automatically exported 2D videos to the user’s camera roll.

Viewing UI details. Feels like regular video player until playing shows depth parallax. UI is available, though muted against content. Menus fade without interaction. Content blurs near device bounds via variable blur shader.
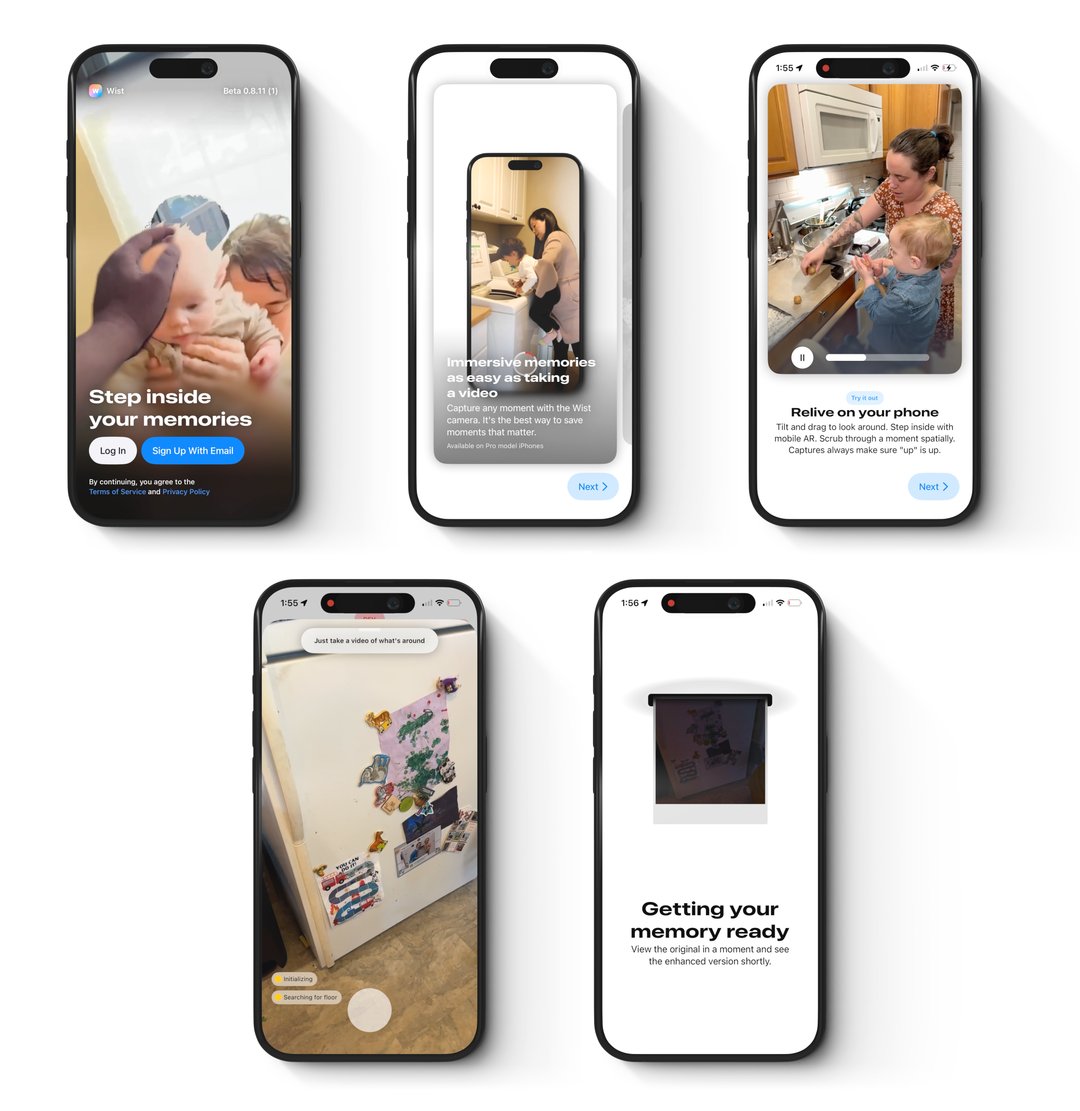
Reduced time to magic during onboarding. Onboarding flow included skimmable feature cards, trying the 3D viewer with one of our featured memories, capturing or importing their first memory, and a instant camera inspired printing animation (and more). This helped users immediately feel the magic and ease of Wist. Then, when they sign in on a headset, their first memory is ready.
Headsets bring you closer to a moment
Quest, Vision ProVideo. Really be there again in a headset for the most powerful experience. On Quest and Vision Pro.
There is an interplay between what we can build, what is performant, and what users expect from sci-fi media.
Headset apps reproject memories back into the user’s space, and if the user is in the same place as the capture, they can realign the virtual content with their real world.
Playback-focused UI prioritizes reliving moments over navigation and viewer options.
Sci-fi insipired, but not distracting visual styling. Critical that we play the memory vividly, lean into user notions of “memory viewers” from sci-fi media (including the artifacts), but we cannot let the styling get in the way of the moment.
Space specific considerations for how the reprojected media intersects a user’s space and their varied intentions while using the app:
- Getting closer to the capture position fades in the culled edges
- Grabbing the memory pauses it and crops in the boundaries of it
- Fluid transitions and looping
Other headset details

Platform experimentation. We shipped different interfaces to test interface variations, partially inspired by platform user expectations. Both had the core concepts: a focus on the memory itself; a small, grabbable player that expands to browse all memories; and deeper options hidden away.
Quest UI soft shadows. I pre-rendered the icon and a blurred version, which allowed us to fake realistic icon shadows.

Blur glow. With the extra compute of the Vision Pro and ease of SwiftUI, the playing memory’s card generates a blurred version of the thumbnail and blends it in as a glow behind the card.

Grabbable memories. Distinct yet intuitive gestures allow for quick, accurate, and forgiving repositioning. Grabbing pauses and fades the memory for a better mix of real and virtual content.

Person highlighting. A view option that hides non-person content, making it feel like the people are back in your space.

Collapsable browsing. Skim captures in the player or expand the browsable area for more focused browsing.
Processing enhances captures
On device & in the cloudA mix of on device and cloud pipeline that reconstructs dynamic spatial scenes from in-the-wild videos.
Our system combined:
- Video
- LiDAR depth (if available)
- Camera pose + intrinsics (if available)
- ML and CV based depth estimation, segmentation, optical flow, +
into an internal format that could capture, encode, and play at 30+fps.
On device
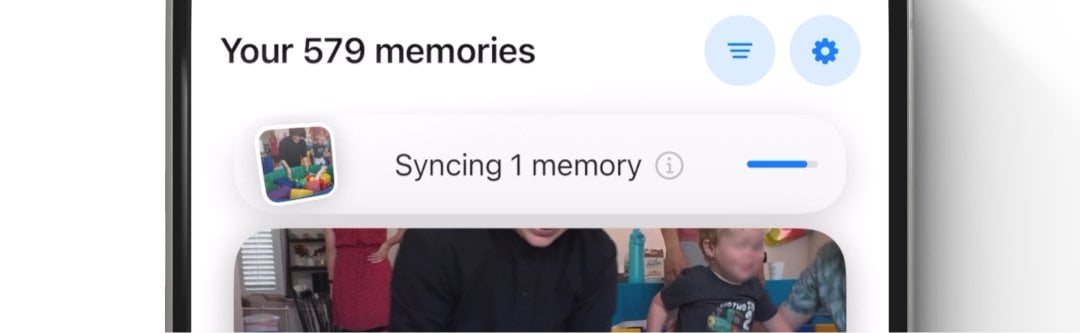
Background sync. Syncing starts as soon as possible to reduce user wait times. Given privacy concerns with personal media, sync card is tappable with additional information about how media is synced across devices.
- Directly encode into our internal formats during capture
- As “backgroundable” as possible
- Ready for immediate playback on iOS and, after syncing, headsets
- Auto-export 2D video to camera roll to decrease switching cost
Backend enhancement
Multi-source informed rectification. Generating different channels of data (depth, flow, segmentation) allowed us to better rectify the final sequence.
We integrated multiple computer vision ML models (depth estimation, camera pose + intrinsics estimation, segmentation, optical flow). We created model and data specific rectification layers and traditional CV techniques to improve temporal coherence and reduce artifacts. Models included Map Anything, Depth Pro, RAFT, FiLM, and more.

Raw LiDAR depth to our enhanced output. More detail is present without losing metric accuracy, and it is more temporally stable.

Data packing into video frames. We experimented with many frame encodings, including this where we pack many “channels” of data into a single frame of video. This unlocked higher quality playback by balancing compute and texture lookups, as well as preserving data fidelity through compression.
One example: LiDAR data is low resolution and highly flickery while ML depth estimation may be higher resolution, but lacks the same metric accuracy. We figured out how to resolve the real world depth sequence from a plethora of data sources, including the two depth sources.
I built a PyTorch-based optimization function that integrated the various data sources based on their unique qualities (e.g. far field LiDAR is low quality) and physical realism (e.g. 3D point movement 3D should have smooth acceleration).
Rerun visualization. I frequently used Rerun to visually validate our pipeline modules. This is my pass at a bundle adjustment solver, an unfinished component I was developing at the end.

Spatial playback allows for perfect realignment with the real world.
Prototypes
Everything was a prototype until it shipped.
Prototyping near field user-to-user interactions to help people feel even closer.
Early shader prototyping for visual look development.
Early movement system focused on direct, contextual "grabbing".

Vivid memory palace. Before Wist, I built a bunch of memory prototypes including a mixed media memory museum. I used photogrammetry scans, spherical photos, DepthKit volumetric video, and flat photos and videos.

Vivid: drive by house scans. I drove by old houses I lived in, captured video, and then created photogrammetry scans to understand what it'd feel like to be able to relive meaningful places from the past.

Vivid: high five. Playful social interactions are always important.
Tradeoffs & challenges
My critical responsibility was figuring out what can we do today that gets us to tomorrow. I used my background across design, eng, and product to find our way forward.
With a tiny team, each item we worked on meant not working on 20 others. We had to be intentional about what we pursued, which fires we left burning, and what would get us to the next step.
Easy, relatively, to know our unique angle: dynamic memories, captured from a phone (optionally with LiDAR), feels like taking a video, just works.
Hard, building the 1,000 parts that lives up to that vision.
My cofounder and I built the scaffolding early (core UX, encoding format, backend processing pipeline), allowing us to improve without changing our architecture.
Low quality LiDAR capture
Knew: LiDAR only capture won't hit the quality level for high retention. Locking to hardware limits scalability.
Considered: On device processing, playback time processing, backend processing.
Decided: Keep on device processing to make captures immediately available, increases trust with users. Build backend processing to hit higher quality bar which will increase retention.
Outcome: Drastically increased quality over hardware-only capture. Allowed us to pursue imported video which increased our potential.
Staging social & multiplayer
Knew: Social+multiplayer is critical to long term retention ... but Wist must succeed as a single player experience first. This would open us to many new problems while trying to solve core capture/processing/playback already.
Considered: Lightweight features that could be small tests. Going all in on social or multiplayer.
Decided: Delay until the core is solid.
Outcome: Looking back, this was directionally the right call but I should have started testing these features earlier.
Expressing depth on a flat screen
Knew: Headsets are the best experience, but people are out and about with their phones. Mobile AR playback was interesting to users ... and confusing.
Considered: No phone playback. Mobile playback limited to AR with new UI. 2D video only playback on mobile.
Decided: Find a few key ways to express depth that adds to the experience. Prototyped a set of mathematical couplings between the 3D scene camera, the user's input, the scrub position, and the playback camera.
Outcome: Feels like a natural extension of 2D video. Swipe, tilt, or scrub to explore the scene without getting lost.
Should the enhancement pipeline be centered on a single ML model or a combination of traditional CV and ML models?
Knew: No one ML model can get full depth+pose+intrinsics well enough to hit the quality level we need (nor is that defensible). Traditional CV is powerful though prone to its own failures. Combining could be more robust ... or could lead to complexity that we won't be able to deal with.
Considered: Open source models. Training our own. Traditional CV techniques. Constellation of methods.
Decided: Constellation of methods. Our unique value is building the end to end system, including orchestration and rectification of the various methods.
Outcome: Built a robust pipeline that rectifies the various data sources against each other (e.g. multiple depth estimators) as well as physical constraints (e.g. motion expectation contraints across the sequence), using both ML models (DepthPro, MapAnything, RAFT, FiLM, +) and traditional CV (filters, SFM, photogrammetry, +).

The only way to navigate tradeoffs in a highly technical and experiential product like Wist is to know the opportunities and constraints across design, eng, product, and R&D.
That’s what makes me special.